はじめに
1つ前に下記の記事を書きましたが,今回はその続きです.
Compute Shaderと頂点バッファの連携の話
https://www.shader.jp/?page_id=2740
前回のサンプルではDirect3D12でCompute Shaderで頂点バッファの書き換えを行って描画するということを紹介しました.このサンプルではCompute Shaderと描画のコマンドリストの積み込みの関数を分けてコマンドリストを分割していました.今回は,それのコードをCompute用のコマンドリストやコマンドキューでの実行に変更してみたいと思います.
今回の記事ではその他にDirect3D12にはもう1つコマンドリストやコマンドキューの種類としてコピー専用のものが存在します.前回のサンプルではCreateVertexBuffer関数内でD3D12_HEAP_TYPE_UPLOADのリソースからD3D12_HEAP_TYPE_DEFAULTにバッファをコピーする処理があったのでCopy処理についても紹介します.
コマンドリスト、コマンドキューの分割
現代のPCやモバイルデバイスコンソールゲーム機はCPUがマルチコアなケースが大半でマルチスレッド処理を使用しやすくなりました.Direct3D12ではそうしたCPU環境からマルチコアを活用する設計にDirect3D11から変わりました.
一方でGPUの方はどうかというともともと並列計算がしやすいような処理になっておりCPUよりも多くの並列計算用の実行ユニットを持っています.しかし,処理の内容によってはGPUの実行ユニットをフル稼働に埋められないケースがあり,その並列計算の能力を生かしきれないケースが出てくることがあります.この時に余っている演算ユニットにCompute Shaderを実行させる仕組みが現代のGPUではできるようになりました.Async Computeとか非同期Computeのような呼ばれ方をする技術です.
もう1つGPUの話になりますが,シェーダの実行の他にGPUではPC側のメインメモリとGPUのローカルVRAMでデータの間をやり取り
このあたりの仕組みはDirect3D12ではマルチエンジンという用語で書きにドキュメントがあります.
マルチエンジンの同期
https://docs.microsoft.com/ja-jp/windows/win32/direct3d12/user-mode-heap-synchronization
コマンドキューの実行状況を見る
本当にコマンドキューが分割されて実行されてるかを見るにはPixやNsightなどのプロファイラで見てみる必要があります.
今回のサンプルについて
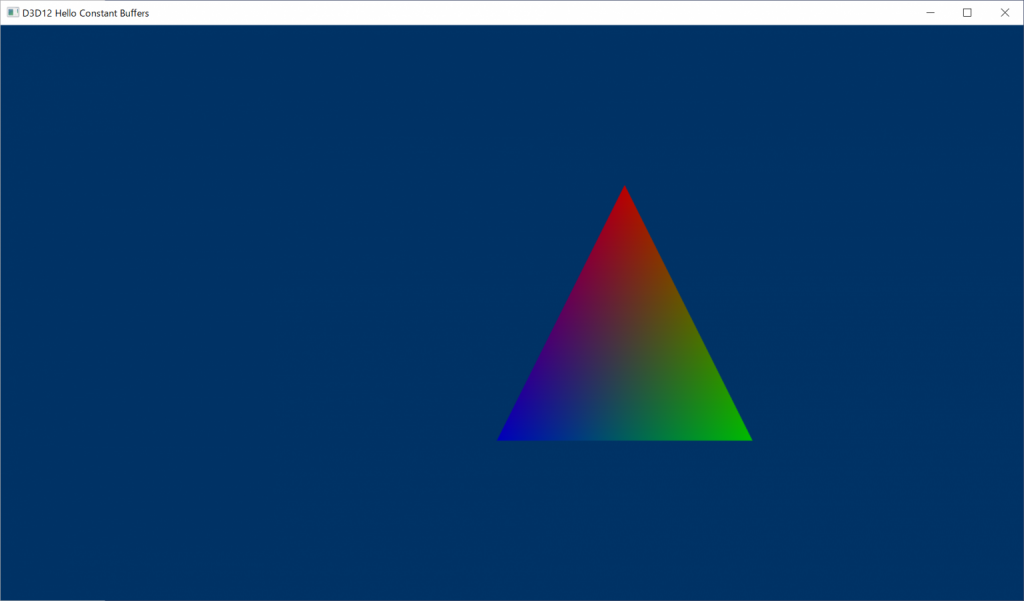
今回のサンプルのリポジトリは下記になります.実行結果として画面に出るものは前回と同じです.三角形が移動しながら色が変わるものです.シェーダ部分は変更はありません.
https://github.com/shaderjp/ShaderjpDirect3D12Samples/tree/master/D3D12ComputeAndCopyQueue
コマンドキュー,コマンドアロケータ,コマンドリストの作成
ComputeやCopyを非同期で実行するためのコマンドキューにはコマンドアロケータやコマンドリストもそれに合わせた設定で作成が必要です.違うフラグで生成したものは警告が出て正しく動作しません.
コマンドキューの作成
まずはコマンドキューの作成ですが,D3D12ComputeAndCopyQueue::LoadPipeline()の中で記載しています.D3D12_COMMAND_QUEUE_DESのTypeで前回まではD3D12_COMMAND_LIST_TYPE_DIRECTを使ってましたが,D3D12_COMMAND_LIST_TYPE_COMPUTEやD3D12_COMMAND_LIST_TYPE_COPYを生成しています.
// Describe and create the command queue.
D3D12_COMMAND_QUEUE_DESC queueDesc = {};
queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
ThrowIfFailed(m_device->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&m_commandQueue)));
//
queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_COMPUTE;
ThrowIfFailed(m_device->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&m_computeCommandQueue)));
//
queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_COPY;
ThrowIfFailed(m_device->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&m_copyCommandQueue)));Code language: C++ (cpp)コマンドアロケータの作成
続いて,コマンドアロケータの作成をしますがこちらもD3D12ComputeAndCopyQueue::LoadPipeline()関数内の最後の方で記載しています.D3D12_COMMAND_LIST_TYPE_COMPUTEやD3D12_COMMAND_LIST_TYPE_COPYといったフラグの指定をします.
ThrowIfFailed(m_device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(&m_commandAllocator)));
ThrowIfFailed(m_device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_COMPUTE, IID_PPV_ARGS(&m_computeCommandAllocator)));
ThrowIfFailed(m_device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_COPY, IID_PPV_ARGS(&m_copyCommandAllocator)));Code language: C++ (cpp)コマンドリストの生成
コマンドリストの作成は,D3D12ComputeAndCopyQueue::LoadAssets()の中で行っています.こちらもComputeやCopy用のフラグを付けるだけです.
ThrowIfFailed(m_device->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_DIRECT, m_commandAllocator.Get(), nullptr, IID_PPV_ARGS(&m_commandList)));
ThrowIfFailed(m_device->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_COMPUTE, m_computeCommandAllocator.Get(), nullptr, IID_PPV_ARGS(&m_computeCommandList)));
ThrowIfFailed(m_device->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_COPY, m_copyCommandAllocator.Get(), nullptr, IID_PPV_ARGS(&m_copyCommandList)));Code language: C++ (cpp)コピー処理
今回のサンプルではD3D12_HEAP_TYPE_DEFAULTフラグの頂点バッファの初期化でコピーのためにCopyResourceしているのでこれをCopyのコマンドキューで実行してみます.前回からCreateVertexBuffer()関数の中を書き換えています.
void D3D12ComputeAndCopyQueue::CreateVertexBuffer()
{
ComPtr<ID3D12Resource> vertexBufferHeap;
UINT vertexBufferSize = 0;
// Create the vertex buffer.
{
// Define the geometry for a triangle.
Vertex triangleVertices[] =
{
{ { 0.0f, 0.25f * m_aspectRatio, 0.0f }, { 1.0f, 0.0f, 0.0f, 1.0f } },
{ { 0.25f, -0.25f * m_aspectRatio, 0.0f }, { 0.0f, 1.0f, 0.0f, 1.0f } },
{ { -0.25f, -0.25f * m_aspectRatio, 0.0f }, { 0.0f, 0.0f, 1.0f, 1.0f } }
};
vertexBufferSize = sizeof(triangleVertices);
// 一時頂点バッファ
ThrowIfFailed(m_device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(vertexBufferSize),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(&vertexBufferHeap)));
// SRVとして使用する頂点バッファ
ThrowIfFailed(m_device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(vertexBufferSize),
D3D12_RESOURCE_STATE_COPY_DEST,
nullptr,
IID_PPV_ARGS(&m_vertexBuffer)));
m_vertexBuffer->SetName(L"vertexBuffer");
// Copy the triangle data to the vertex buffer.
UINT8* pVertexDataBegin;
CD3DX12_RANGE readRange(0, 0); // We do not intend to read from this resource on the CPU.
ThrowIfFailed(vertexBufferHeap->Map(0, &readRange, reinterpret_cast<void**>(&pVertexDataBegin)));
memcpy(pVertexDataBegin, triangleVertices, sizeof(triangleVertices));
vertexBufferHeap->Unmap(0, nullptr);
// Initialize the vertex buffer view.
m_vertexBufferView.BufferLocation = m_vertexBuffer->GetGPUVirtualAddress();
m_vertexBufferView.StrideInBytes = sizeof(Vertex);
m_vertexBufferView.SizeInBytes = vertexBufferSize;
CD3DX12_CPU_DESCRIPTOR_HANDLE handle(m_resouceHeap->GetCPUDescriptorHandleForHeapStart());
handle.Offset(static_cast<int>(SampleHeapIndex::SrcVertexSRV), m_descripterIncrementSize);
D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc;
srvDesc.Format = DXGI_FORMAT_UNKNOWN;
srvDesc.ViewDimension = D3D12_SRV_DIMENSION_BUFFER;
srvDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;
srvDesc.Buffer.FirstElement = 0;
srvDesc.Buffer.NumElements = _countof(triangleVertices);
srvDesc.Buffer.StructureByteStride = sizeof(Vertex);
srvDesc.Buffer.Flags = D3D12_BUFFER_SRV_FLAG_NONE;
m_device->CreateShaderResourceView(m_vertexBuffer.Get(), &srvDesc, handle);
// キャッシュ用頂点バッファ(Compute Shaderの計算結果書き込み用)
// 描画用にはこっちを使う
ThrowIfFailed(m_device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(vertexBufferSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS),
D3D12_RESOURCE_STATE_UNORDERED_ACCESS,
nullptr,
IID_PPV_ARGS(&m_cacheVertexBuffer)));
m_cacheVertexBuffer->SetName(L"cacheVertexBuffer");
m_cacheVertexBufferView.BufferLocation = m_cacheVertexBuffer->GetGPUVirtualAddress();
m_cacheVertexBufferView.StrideInBytes = sizeof(Vertex);
m_cacheVertexBufferView.SizeInBytes = vertexBufferSize;
D3D12_UNORDERED_ACCESS_VIEW_DESC uavDesc{};
uavDesc.Format = DXGI_FORMAT_UNKNOWN;
uavDesc.ViewDimension = D3D12_UAV_DIMENSION_BUFFER;
uavDesc.Buffer.NumElements = _countof(triangleVertices);
uavDesc.Buffer.StructureByteStride = sizeof(Vertex);
CD3DX12_CPU_DESCRIPTOR_HANDLE uavHandle(m_resouceHeap->GetCPUDescriptorHandleForHeapStart());
uavHandle.Offset(static_cast<int>(SampleHeapIndex::CacheVertexUAV), m_descripterIncrementSize);
m_device->CreateUnorderedAccessView(m_cacheVertexBuffer.Get(), nullptr, &uavDesc, uavHandle);
}
// 一時頂点バッファからコピーを行う
ThrowIfFailed(m_copyCommandAllocator->Reset());
ThrowIfFailed(m_copyCommandList->Reset(m_copyCommandAllocator.Get(), nullptr));
// Copyコマンドリストではではリソースバリアは使用不可
// m_copyCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(m_vertexBuffer.Get(), D3D12_RESOURCE_STATE_GENERIC_READ, D3D12_RESOURCE_STATE_COPY_DEST));
m_copyCommandList->CopyResource(m_vertexBuffer.Get(), vertexBufferHeap.Get());
// Copyコマンドリストではリソースバリアは使用不可
// m_copyCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(m_vertexBuffer.Get(), D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE));
ThrowIfFailed(m_copyCommandList->Close());
ID3D12CommandList* ppCopyCommandLists[] = { m_copyCommandList.Get() };
m_copyCommandQueue->ExecuteCommandLists(_countof(ppCopyCommandLists), ppCopyCommandLists);
m_fenceValue = 1;
UINT64 fence = m_fenceValue;
ThrowIfFailed(m_device->CreateFence(0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&m_fence)));
ThrowIfFailed(m_copyCommandQueue->Signal(m_fence.Get(), fence));
ThrowIfFailed(m_commandAllocator->Reset());
ThrowIfFailed(m_commandList->Reset(m_commandAllocator.Get(), nullptr));
m_commandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(m_vertexBuffer.Get(), D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE));
m_commandList->Close();
ThrowIfFailed(m_commandQueue->Wait(m_fence.Get(), fence));
m_fenceValue++;
ID3D12CommandList* ppCommandLists[] = { m_commandList.Get() };
m_commandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
fence = m_fenceValue;
ThrowIfFailed(m_commandQueue->Signal(m_fence.Get(), fence));
m_fenceValue++;
ThrowIfFailed(m_commandQueue->Wait(m_fence.Get(), fence));
}
Code language: C++ (cpp)Copyコマンドリストとコマンドキューの使い方はDirectの時と一見変わらないのですが,実は大きな違いとしてResourceBarrierが使えない点です.
コピー時にはD3D12_RESOURCE_STATE_COPY_DESTでCompute ShaderでのSRVでの読み出し時はリソースステートをD3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCEに変える必要があるのですが,これはCopy Queueではできません.
今回のサンプルではCopyキューでExecuteCommandListsしたらその終了後にDirectキューでリソースバリアをしています.この時にGPU内のCopyキュー内のコピーコマンドが完了したこと待ってリソースバリアでリソースステートを変えたいのでSignalとWaitという関数でフェンスという仕組みを使って処理待ちをします.
Compute
ここでも注意事項はリソースバリアが使えない点ですね.Computeで使用したリソースのリソースステートの変更はD3D12ComputeAndCopyQueue::PopulateComputeCommandList()でしています.
void D3D12ComputeAndCopyQueue::PopulateComputeCommandList()
{
ThrowIfFailed(m_computeCommandAllocator->Reset());
ThrowIfFailed(m_computeCommandList->Reset(m_computeCommandAllocator.Get(), m_computePipelineState.Get()));
// Computeコマンドリストではリソースバリアは使用不可
// m_computeCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(m_cacheVertexBuffer.Get(), D3D12_RESOURCE_STATE_GENERIC_READ, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
ID3D12DescriptorHeap* ppHeaps[] = { m_resouceHeap.Get() };
m_computeCommandList->SetDescriptorHeaps(_countof(ppHeaps), ppHeaps);
m_computeCommandList->SetComputeRootSignature(m_computeRootSignature.Get());
CD3DX12_GPU_DESCRIPTOR_HANDLE handle;
handle = m_resouceHeap->GetGPUDescriptorHandleForHeapStart();
handle.Offset(static_cast<INT>(SampleHeapIndex::ComputeCbv), m_descripterIncrementSize);
m_computeCommandList->SetComputeRootDescriptorTable(0, handle);
m_computeCommandList->Dispatch(1, 1, 1);
// Computeコマンドリストではリソースバリアは使用不可
// m_computeCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(m_cacheVertexBuffer.Get(), D3D12_RESOURCE_STATE_UNORDERED_ACCESS, D3D12_RESOURCE_STATE_GENERIC_READ));
ThrowIfFailed(m_computeCommandList->Close());
}Code language: C++ (cpp)コマンドの実行
D3D12ComputeAndCopyQueue::OnRender()でコマンドキューの実行を行っています.
ところでちょっとした小ネタですが,Direct3D12ではコマンドリストの積み込み自体はスレッドセーフになったのでC++11のstd::threadでComputeと描画のコマンドリストを積む関数をスレッド分けしても特に問題ありません.
void D3D12ComputeAndCopyQueue::OnRender()
{
std::thread thread[2];
thread[0] = std::thread(&D3D12ComputeAndCopyQueue::PopulateComputeCommandList, this);
thread[1] = std::thread(&D3D12ComputeAndCopyQueue::PopulateCommandList, this);
for (int i = 0; i < 2; i++)
{
thread[i].join();
}
ID3D12CommandList* ppComputeCommandLists[] = { m_computeCommandList.Get() };
m_computeCommandQueue->ExecuteCommandLists(_countof(ppComputeCommandLists), ppComputeCommandLists);
UINT64 fence = m_fenceValue;
ThrowIfFailed(m_computeCommandQueue->Signal(m_fence.Get(), fence));
m_fenceValue++;
ThrowIfFailed(m_commandQueue->Wait(m_fence.Get(), fence));
// Execute the command list.
ID3D12CommandList* ppCommandLists[] = { m_commandList.Get() };
m_commandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
// Present the frame.
ThrowIfFailed(m_swapChain->Present(1, 0));
WaitForPreviousFrame();
}Code language: PHP (php)コマンドキューとコマンドリストのキャプチャ
コマンドキューとコマンドリストの分離のNSight Graphicsでキャプチャしてみました.今回のサンプルでDirectのコマンドキューは赤でくくった個所で,緑がComputeの処理です.使われてるコマンドキューが違うのがわかります.
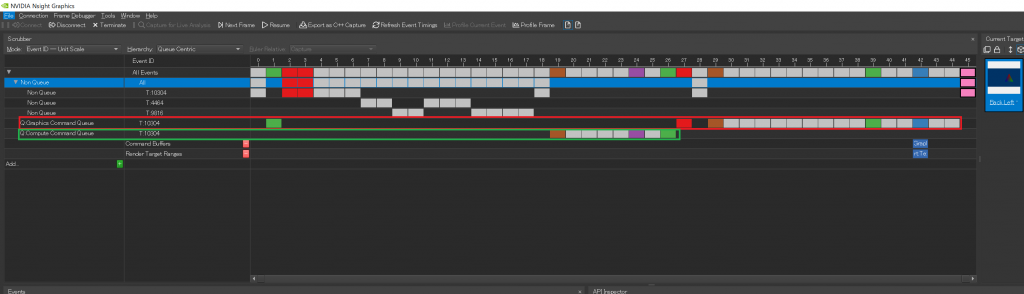
前回のサンプルも見てます。前回は1つのコマンドキューということで今回分離したものが1つのコマンドキューで実行されてるのがわかります.
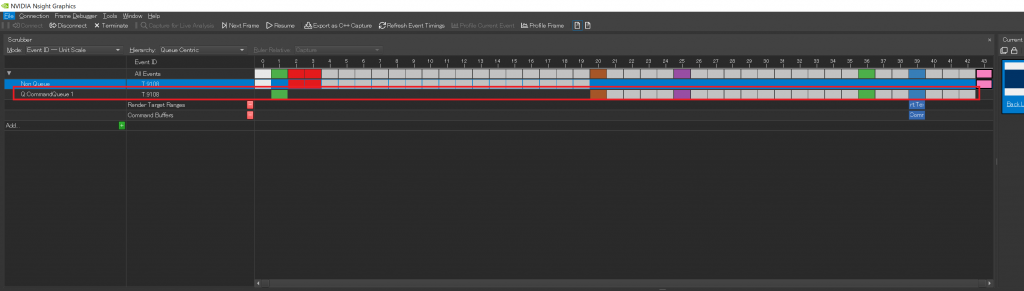
今回はDirectとComputeのコマンドキューの処理を並列に実行するようにはしていません.きれいにGPUを使いきるにはこの辺り空いた状態をみっちりコマンドが埋まる形を目指したいですね.
おわりに
本来はこの記事ではCompute Queueのみを扱う予定でしたが,ちょうど前回CopyResourceを使用していたのでCopy Queueも扱うことができました.
複数のパスで使いまわすリソースやコマンドキューのSignalとWaitでやり取りするフェンス値のことなどややこしいことがわかったかと思います.今回はシングルスレッドのところでやったのでベタに書いてますが,あまりいい実装にはなっていません(意図したものとして).
複数の種類のコマンドキューを織り交ぜたエンジンの制作にはマルチコアCPUを活用した設計にしないといけない部分はありますし,全体の処理の中でGPUの実行ユニットの占有率を見ながら余剰があるときに非同期Computeを挟み込むみたいな話がありますが,今回はさすがにそのあたりまでは触れられませんでした.
これら描画エンジンのマルチスレッド化のややこしい話の解決にはGDC 2017のEA FrostbiteチームのFrameGraphを参考に検討してみることが多いのではないかと思います.